ML Engineering Projects
Real-Time Personalization Engine
High-performance recommendation system with sub-100ms latency
Overview
This personalization engine processes user events in real-time to generate personalized recommendations. Built for scale, it handles 50K+ requests per second while maintaining sub-100ms response times.
Key Features
- Real-time event processing with Kafka streaming
- Redis-based caching for ultra-low latency
- XGBoost models for recommendation scoring
- A/B testing framework for continuous optimization
- Comprehensive monitoring and alerting
Architecture
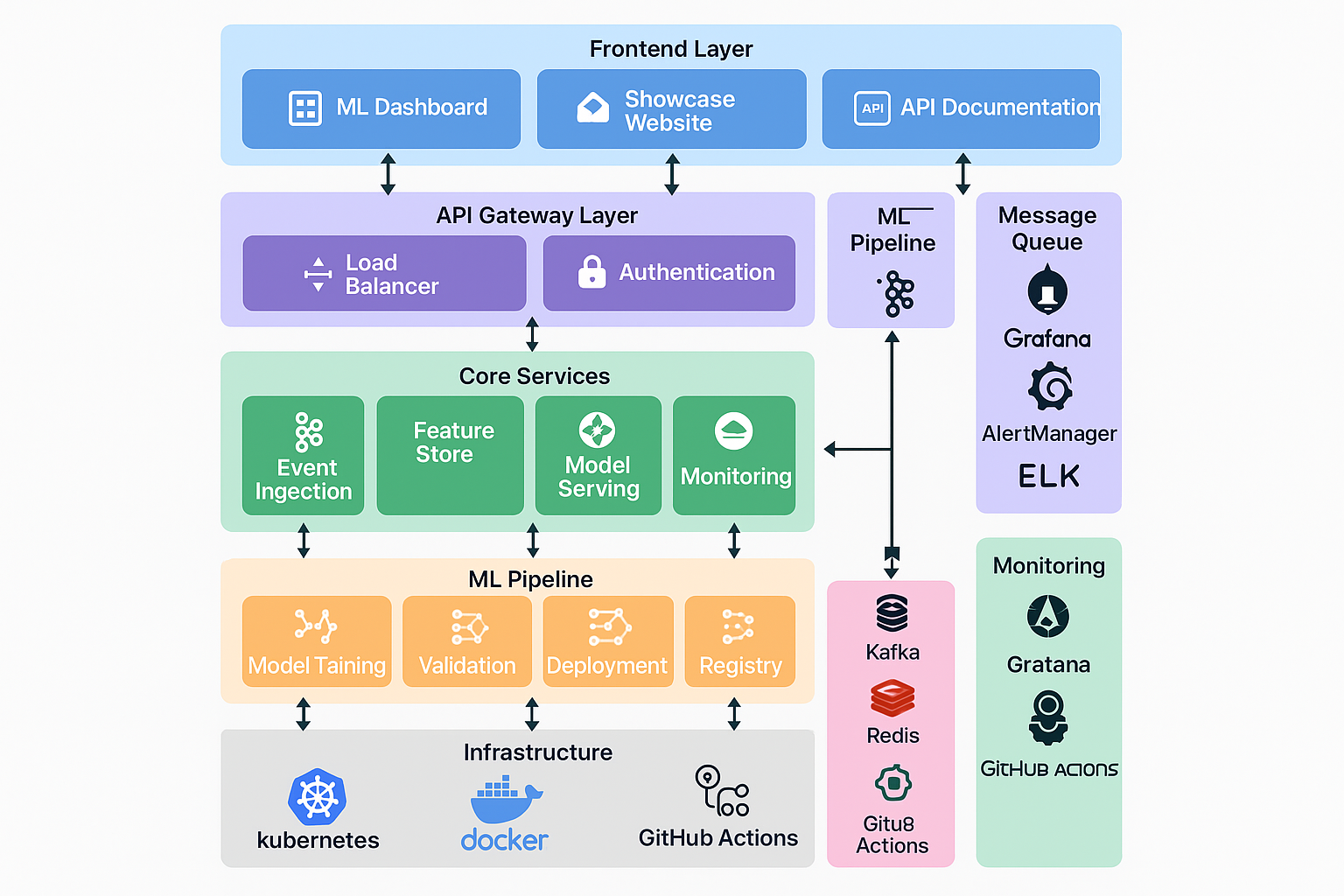
Sample API Usage
MLOps Pipeline & CI/CD
Automated ML lifecycle management with GitHub Actions
Overview
Comprehensive MLOps pipeline that automates the entire ML lifecycle from data validation to model deployment. Features automated testing, versioning, and blue-green deployments.
Pipeline Stages
- Data Validation - Automated data quality checks and drift detection
- Model Training - Distributed training with hyperparameter optimization
- Model Validation - Comprehensive testing including A/B tests
- Deployment - Blue-green deployment with automatic rollback
- Monitoring - Real-time performance tracking and alerting
CI/CD Configuration
Scalable Feature Store
Enterprise-grade feature management system
Overview
Centralized feature store that manages features for all ML models. Provides consistent feature computation, versioning, and lineage tracking with both batch and real-time serving capabilities.
Key Capabilities
- Dual storage architecture (PostgreSQL for batch, Redis for real-time)
- Feature versioning and lineage tracking
- Point-in-time correct feature retrieval
- Feature monitoring and data quality checks
- SDK for Python, Java, and Go
Feature Definition Example
Interactive ML Dashboard
Comprehensive monitoring and analytics platform
Overview
Full-featured dashboard for monitoring ML models in production. Provides real-time metrics, performance analytics, and business intelligence insights.
Dashboard Features
- Model Explorer - Compare model versions and performance
- Feature Analytics - Feature importance and drift monitoring
- Performance Monitoring - Real-time metrics and alerts
- Business Insights - ROI analysis and impact metrics
Technologies Used
- Streamlit for interactive UI
- Plotly for advanced visualizations
- Prometheus for metrics collection
- Real-time WebSocket updates
Dynamic Rules Engine
High-performance business rules execution system
Overview
Flexible rules engine that allows business users to define and modify rules without code changes. Built with Go for maximum performance, it evaluates complex rule sets in under 1ms.
Features
- DSL for rule definition
- Real-time rule updates via etcd
- A/B testing framework
- Comprehensive rule analytics
- gRPC API for high throughput
Rule Definition Example
Performance Metrics
- Rule evaluation: <1ms average
- Throughput: 100K+ evaluations/second
- Rule hot-reload: <100ms
- Memory usage: <100MB for 1000 rules